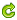-
1191233050_n.jpg (176.76 KB, 下载次数: 51)

1191233050_n.jpg (176.76 KB, 下载次数: 51)

王不留 发表于 2016-1-24 10:53
不准,不准。。。
scientist排不上最好的list很正常。。
居然在最差的列表里也没有!!。。


煮酒正熟 发表于 2016-1-24 11:47
一脚门里一脚门外的也算?

晨枫 发表于 2016-1-24 12:48
怎么不算?算!别废话了,发红包吧!

holycow 发表于 2016-1-24 11:46
晨大小白了,UX就是User Interface。Solution Architect就是老兵他老板。
还有,工程咨询公司来接你们生意 ...

煮酒正熟 发表于 2016-1-24 11:49
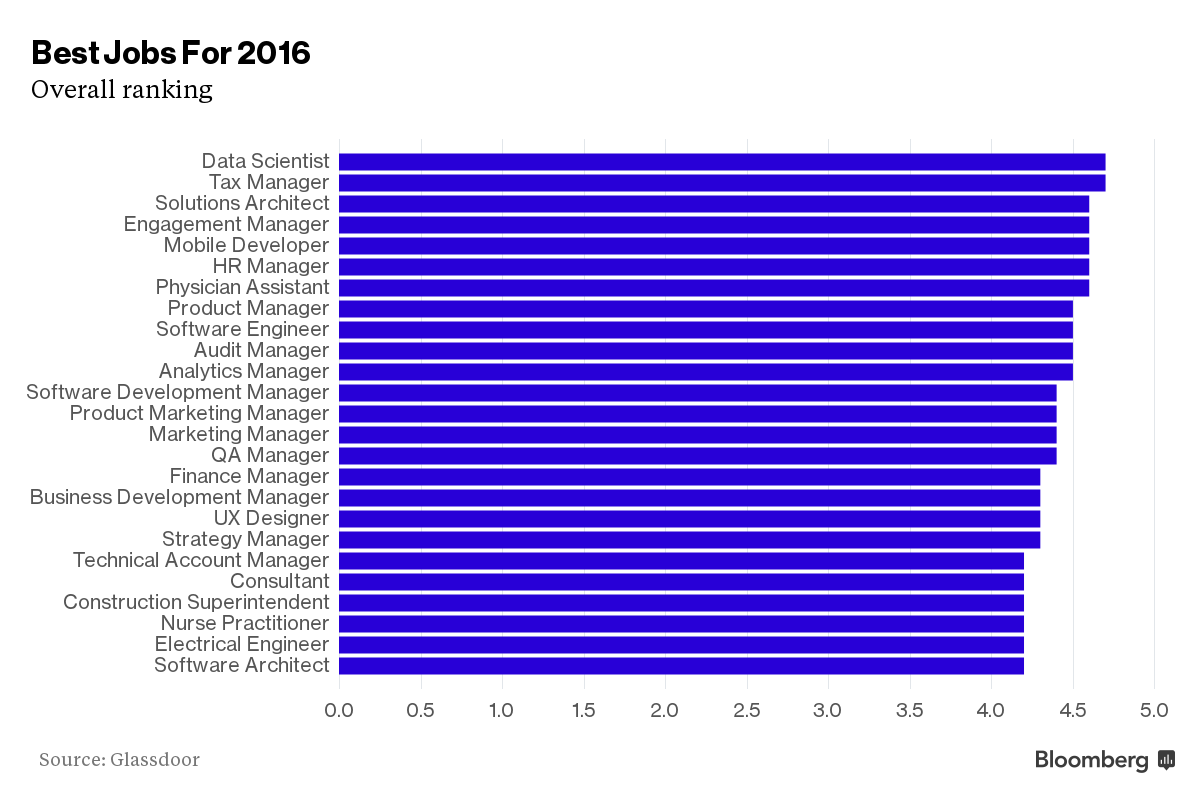
半个数据科学家只有人家一半儿的工资,和各位同学一比简直是弱爆了 ...

fcboliver 发表于 2016-1-24 13:20
你以为老酒家一屋子的路易13家俱哪来的?
晨枫 发表于 2016-1-24 09:47
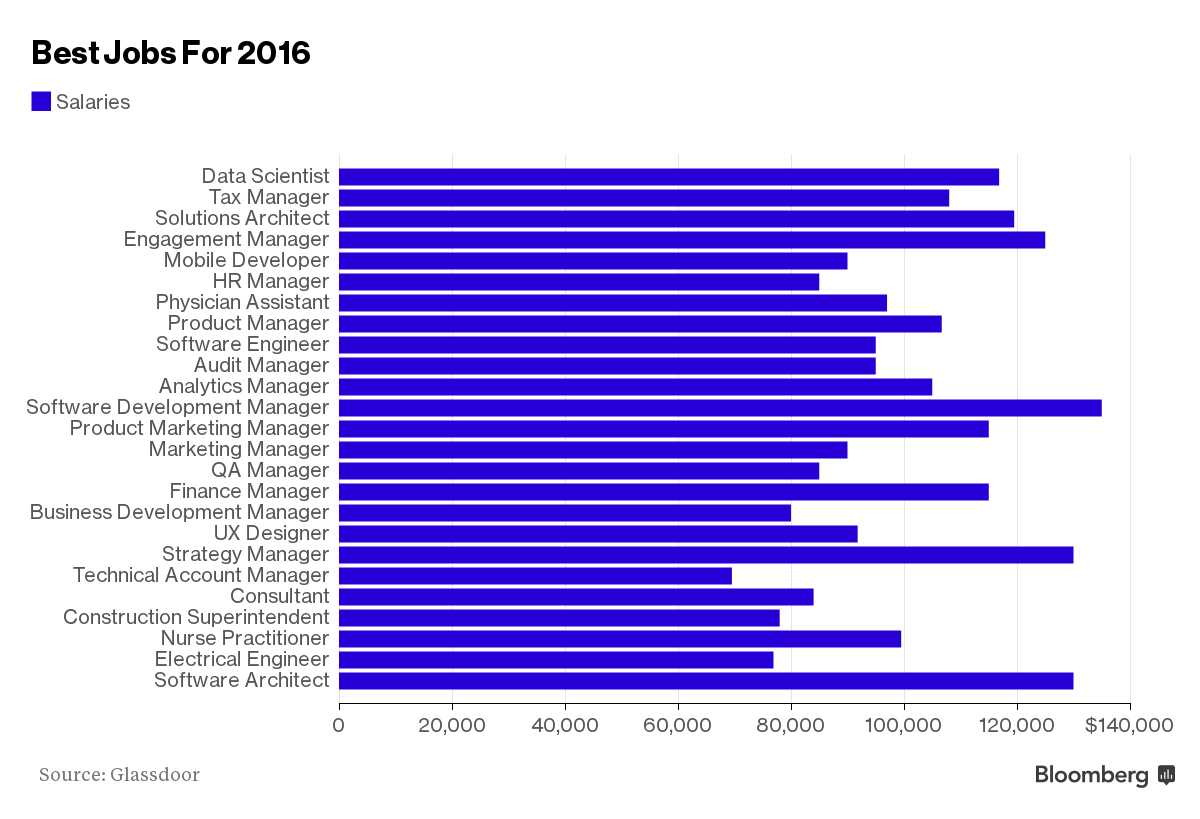
scientist比酒店管理和记者还是强啦。

晨枫 发表于 2016-1-24 09:49
埋头拉车惯了,对这些云里雾里的头衔,我总是不甚了了。
holycow 发表于 2016-1-24 12:40
car dealer居然榜上无名


holycow 发表于 2016-1-24 12:46
晨大小白了,UX就是User Interface。Solution Architect就是老兵他老板。
还有,工程咨询公司来接你们生意 ...
holycow 发表于 2016-1-24 14:22
更正一下,UX是User eXperience, 手快写错了
老马丁 发表于 2016-1-24 14:42
这些工作不是商学院就是IT。Come and go. 我知道加拿大起码10所大学正打算设置大数据的硕士。过几年又大白 ...
晨枫 发表于 2016-1-24 15:37
那不算professional job,不算,否则retail associate也也算进去啦。

修业 发表于 2016-1-25 06:58
做过美股日内交易员,入行一年比前三名收入高很多
老兵帅客 发表于 2016-1-25 06:22
瞎说,我老板可不是什么Solution Architect,人家是director。至于Solution Architect嘛,我见过的加拿大 ...
holycow 发表于 2016-1-25 10:35
你老板以director的title,整天干Solution Architect的事,而且还干得不怎么样 ...
光头佬 发表于 2016-1-25 03:40
请问楼主,文中提到的薪水是年薪还是月薪?难道花街那些交易员不在列表中吗? ...
老兵帅客 发表于 2016-1-25 09:26
已经大白菜了,俺们土狼屯的小公司里面,一堆的big data specialist,张嘴一聊,连基本的数据库概念都没 ...
煮酒正熟 发表于 2016-1-25 18:08
这个问题要辩证地来看,发展地来看。不过在开侃之前俺先表个态:俺跟你是一伙儿的,根子在数据库和数据方 ...


煮酒正熟 发表于 2016-1-25 18:08
这个问题要辩证地来看,发展地来看。不过在开侃之前俺先表个态:俺跟你是一伙儿的,根子在数据库和数据方 ...
老兵帅客 发表于 2016-1-25 19:42
别着急,您还记得当年的web developer吧,也就是会写点页面那玩意儿的,也能挣大钱,不过没几年而已。那 ...
煮酒正熟 发表于 2016-1-25 20:42
大数据和当年的web developer很不一样。web developer有吮马根基啊?纯属花拳绣腿。今天的大数据则是有根 ...
老兵帅客 发表于 2016-1-25 21:10
不要那么贬低web developer,要是没有底层那些支持,例如多线程、javascript的底层东西,还有dreamweaver ...
煮酒正熟 发表于 2016-1-26 09:42
大数据和当年的web developer很不一样。web developer有吮马根基啊?纯属花拳绣腿。今天的大数据则是有根 ...
煮酒正熟 发表于 2016-1-25 21:44
老兵对大数据的了解似乎有待加深啊... 数据科学家的工作,说到底,有较大艺术成份。诚然,拉数据(data qu ...
煮酒正熟 发表于 2016-1-25 19:42
大数据和当年的web developer很不一样。web developer有吮马根基啊?纯属花拳绣腿。今天的大数据则是有根 ...
晨枫 发表于 2016-1-25 22:09
统计我学过点,机器学习也能蒙哥大概,但老酒给说说吧,这个数据到底是怎么回事? ...
老兵帅客 发表于 2016-1-25 21:10
简单地讲就是data mining,不过是分布式的。这里的关键是建模,然后用算法找出data pattern来。 ...
晨枫 发表于 2016-1-25 22:13
那怎么解决数据的相关性和causality问题呢?
晨枫 发表于 2016-1-25 19:13
那怎么解决数据的相关性和causality问题呢?
老兵帅客 发表于 2016-1-25 22:01
刚才我抽时间看了一下大数据相关的事情,感觉就是云计算、分布计算基础上的data mining,而data mining的 ...
煮酒正熟 发表于 2016-1-25 22:35
软件开发当然是艺术性的活动(虽然我没做过)。
你第一段说的那些,不错,都是大数据范畴,而且你说的也 ...
晨枫 发表于 2016-1-25 22:13
那怎么解决数据的相关性和causality问题呢?
老兵帅客 发表于 2016-1-25 19:43
一个疑问,“要求从业人员对商业问题与数据之间的转化和关联有深刻和细微的体察”,这种经验应该是与行业 ...
晨枫 发表于 2016-1-25 22:13
那怎么解决数据的相关性和causality问题呢?
煮酒正熟 发表于 2016-1-25 01:49
半个数据科学家只有人家一半儿的工资,和各位同学一比简直是弱爆了 ...
老兵帅客 发表于 2016-1-25 22:43
一个疑问,“要求从业人员对商业问题与数据之间的转化和关联有深刻和细微的体察”,这种经验应该是与行业 ...
老兵帅客 发表于 2016-1-25 21:17
我以前做过一些data mining方面的事情,通过适当的建模和数据选取可以有效地减少你所说的问题,但是代价 ...
holycow 发表于 2016-1-25 21:32
模型只解决相关性,不解决因果性。解决因果性的是人脑袋
煮酒正熟 发表于 2016-1-25 21:35
软件开发当然是艺术性的活动(虽然我没做过)。
你第一段说的那些,不错,都是大数据范畴,而且你说的也 ...
说到底,实际上是商业问题研究的一个延伸,是商业向数据要答案的这样一个延伸。由于这个商业本质(商业 近乎 艺术),要求从业人员对商业问题与数据之间的转化和关联有深刻和细微的体察,
煮酒正熟 发表于 2016-1-25 21:52
神牛说的对。模型只能找出存在相关性的因素来。比如最常见的general linear model,左边一个y,右边一长 ...
煮酒正熟 发表于 2016-1-25 22:04
上面那个例子是基于传统的商业问题的回答。对于这种问题,传统的建模手段就是经典统计学的(比如SAS)。 ...
晨枫 发表于 2016-1-25 21:02
模型只解决输入数据和输出数据之间的相关性,对于输入数据内在的相关性还是抓瞎;因果性不来自人的脑袋, ...

holycow 发表于 2016-1-25 23:23
你这个是自动控制的角度,大数据的model的用处,是present给决策者各种相关性,这些相关性当然是因果性的 ...
晨枫 发表于 2016-1-25 21:23
classic stats我的理解就是parametric modeling,machine learning是non-parametric的吗?可以和神经元类 ...
晨枫 发表于 2016-1-26 00:12
哈,这就和我的理解差不多了。我对这些机器学习、人工智能从来不相信,they have their places, but the ...
晨枫 发表于 2016-1-25 21:25
哈,抬头往上看58楼。
有点理解为什么花街那么screwed up了。
晨枫 发表于 2016-1-26 00:18
你这些都没有问题,模型就是界定输入数据和输出数据之间的相关性的,问题出在输入数据集内部存在相关性。 ...
煮酒正熟 发表于 2016-1-26 13:30
我对机器学习的了解也很粗浅。以我粗浅的了解来说,这个东西肯定不是吮马silver bullet或是万能解药,而 ...
煮酒正熟 发表于 2016-1-25 23:30
我对机器学习的了解也很粗浅。以我粗浅的了解来说,这个东西肯定不是吮马silver bullet或是万能解药,而 ...
holycow 发表于 2016-1-25 23:37
模型搞到最后,已经不是人脑能够理解的了,it's a runaway train~~
煮酒正熟 发表于 2016-1-25 23:41
你说的是multi-collinearity吗?
建模的程序通常是 ---
晨枫 发表于 2016-1-26 00:51
这就不可能是好模型……
holycow 发表于 2016-1-25 22:59
做企业级应用的人,不管做不做大数据,市场价值都是两部分组成的:技术能力和行业经验。因此你这个问题对 ...

煮酒正熟 发表于 2016-1-25 23:04
上面那个例子是基于传统的商业问题的回答。对于这种问题,传统的建模手段就是经典统计学的(比如SAS)。 ...
煮酒正熟 发表于 2016-1-26 00:30
我对机器学习的了解也很粗浅。以我粗浅的了解来说,这个东西肯定不是吮马silver bullet或是万能解药,而 ...
禅人 发表于 2016-1-26 00:48
linked-in顾名思义就是要把你我她他扯在一起嘛。记得我对你说过,这几个人与你link的节点,估计就是各自留 ...
晨枫 发表于 2016-1-26 00:51
这就不可能是好模型……
Big data usually includes data sets with sizes beyond the ability of commonly used software tools to capture, curate, manage, and process data within a tolerable elapsed time.[13] Big data "size" is a constantly moving target, as of 2012 ranging from a few dozen terabytes to many petabytes of data. Big data requires a set of techniques and technologies with new forms of integration to reveal insights from datasets that are diverse, complex, and of a massive scale.[14]
In a 2001 research report[15] and related lectures, META Group (now Gartner) analyst Doug Laney defined data growth challenges and opportunities as being three-dimensional, i.e. increasing volume (amount of data), velocity (speed of data in and out), and variety (range of data types and sources). Gartner, and now much of the industry, continue to use this "3Vs" model for describing big data.[16] In 2012, Gartner updated its definition as follows: "Big data is high volume, high velocity, and/or high variety information assets that require new forms of processing to enable enhanced decision making, insight discovery and process optimization."[17] Gartner's definition of the 3Vs is still widely used, and in agreement with a consensual definition that states that "Big Data represents the Information assets characterized by such a High Volume, Velocity and Variety to require specific Technology and Analytical Methods for its transformation into Value".[18] Additionally, a new V "Veracity" is added by some organizations to describe it,[19] revisionism challenged by some industry authorities.[20] The 3Vs have been expanded to other complementary characteristics of big data:[21][22]
Volume: big data doesn't sample; it just observes and tracks what happens
Velocity: big data is often available in real-time
Variety: big data draws from text, images, audio, video; plus it completes missing pieces through data fusion
Machine Learning: big data often doesn't ask why and simply detects patterns[23]
Digital footprint: big data is often a cost-free byproduct of digital interaction[22]
The growing maturity of the concept more starkly delineates the difference between big data and Business Intelligence:[24]
Business Intelligence uses descriptive statistics with data with high information density to measure things, detect trends, etc..
Big data uses inductive statistics and concepts from nonlinear system identification[25] to infer laws (regressions, nonlinear relationships, and causal effects) from large sets of data with low information density[26] to reveal relationships and dependencies, or to perform predictions of outcomes and behaviors.[25][27]
In a popular tutorial article published in IEEE Access Journal,[28] the authors classified existing definitions of big data into three categories: Attribute Definition, Comparative Definition and Architectural Definition. The authors also presented a big-data technology map that illustrates its key technological evolutions.
冰蚁 发表于 2016-1-26 08:30
大数据目前处于非常原始的阶段,和以前的统计/ data mining并没有特别显著的区别。大部分公司挂个大数据的 ...
冰蚁 发表于 2016-1-26 09:30
大数据目前处于非常原始的阶段,和以前的统计/ data mining并没有特别显著的区别。大部分公司挂个大数据的 ...
冰蚁 发表于 2016-1-26 09:30
大数据目前处于非常原始的阶段,和以前的统计/ data mining并没有特别显著的区别。大部分公司挂个大数据的 ...


冰蚁 发表于 2016-1-26 09:30
大数据目前处于非常原始的阶段,和以前的统计/ data mining并没有特别显著的区别。大部分公司挂个大数据的 ...
晨枫 发表于 2016-1-26 09:52
有点联想起自控里在80年代很流行的“大系统理论”了,那时也说是系统大到超过传统数学控制理论的尺度,所 ...
晨枫 发表于 2016-1-26 09:52
有点联想起自控里在80年代很流行的“大系统理论”了,那时也说是系统大到超过传统数学控制理论的尺度,所 ...
MacArthur 发表于 2016-1-26 10:02
“BIG DATA”正在慢慢被这帮人给玩臭了。。。
利用CEO们对于技术上最新潮词又恨又怕又不得不装得很in的 ...

煮酒正熟 发表于 2016-1-26 10:03
以我个人在我们公司成立21个月的Data Science (数据科学)部门的观感来说,在大数据/数据科学这一行里, ...

老兵帅客 发表于 2016-1-26 09:05
当年的软件界还时髦过第四代语言和CASE tools呢,结果后来证明根本行不通。为啥,因为复杂度简单了没事, ...
冰蚁 发表于 2016-1-26 09:08
我觉得大概是稀疏矩阵啥的应该已经做进软件,成为日常工具了,所以就不提了。
因果啥的,理论上以后要靠 ...

橘子和枪 发表于 2016-1-26 10:23
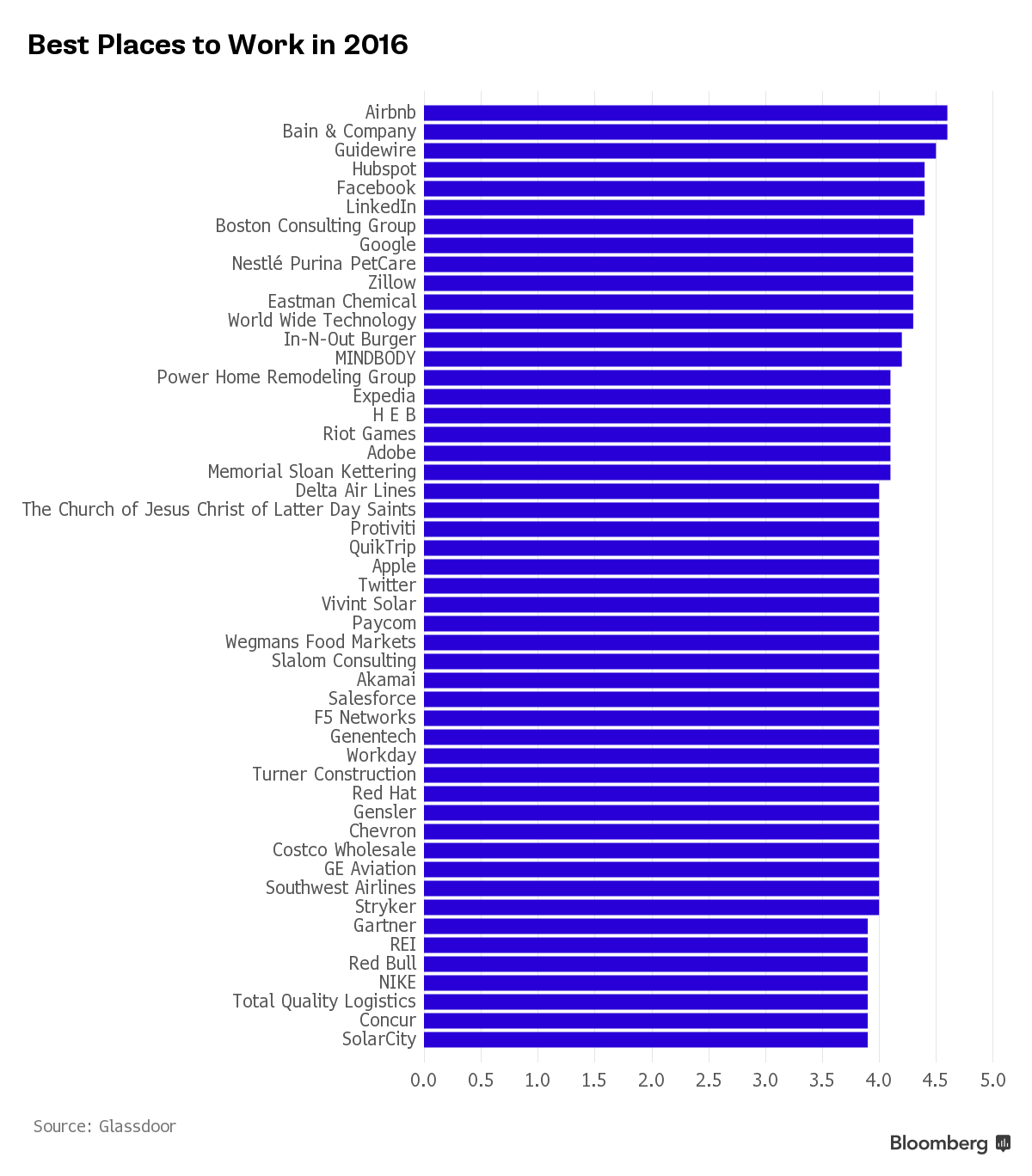
弱弱的问一句,最后一张图里面,那个名字最长的,什么church的也算是一个工作嘛? ...
煮酒正熟 发表于 2016-1-26 07:08
这个问题要辩证地来看,发展地来看。不过在开侃之前俺先表个态:俺跟你是一伙儿的,根子在数据库和数据方 ...

煮酒正熟 发表于 2016-1-26 23:03
以我个人在我们公司成立21个月的Data Science (数据科学)部门的观感来说,在大数据/数据科学这一行里, ...
老兵帅客 发表于 2016-1-26 07:11
公开诳人啊。
holycow 发表于 2016-1-26 11:53
开个逼格达挞群吧,过几个月又可以卖勋章了
holycow 发表于 2016-1-26 11:53
开个逼格达挞群吧,过几个月又可以卖勋章了
老兵帅客 发表于 2016-1-26 09:03
逼格达挞群成立了,欢迎加入!http://www.aswetalk.net/bbs/forum.php?mod=group&action=manage&fid=220 ...

holycow 发表于 2016-1-26 12:05
骗子!没权限加入
晨枫 发表于 2016-1-26 11:13
哈哈,你对人工智能是一如既往地力挺啊。
holycow 发表于 2016-1-26 12:05
骗子!没权限加入
holycow 发表于 2016-1-25 01:46
晨大小白了,UX就是User Interface。Solution Architect就是老兵他老板。
还有,工程咨询公司来接你们生意 ...
杂役头儿 发表于 2016-1-26 20:00
这里的engagement mgr,是说people engagement还是业务类别的呀?
| 欢迎光临 爱吱声 (http://www.aswetalk.net/bbs/) | Powered by Discuz! X3.2 |